C++20 Coroutines Optimization Opportunities from Compiler's perspective
The post was written in Chinese and translated by LLM. Feel free to contact me if any phrasing seems unnatural.
Here is the translation of the article into English.
- Clang/LLVM’s Implementation Choice for Coroutines
- Coroutine Frame Generation & Tips for Reducing Frame Size
- HALO & CoroElide
- noexcept
- Coro RVO
- await_suspend Execution Happens After Coroutine Suspension
- initial_suspend != always_suspend Generates More Code and Blocks CoroElide
- [[clang::coro_only_destroy_when_complete]]
- CIR
- Conclusion
In 2026, C++20 Coroutines are no longer new. However, articles discussing C++20 Coroutines from a compiler’s perspective remain scarce. This post aims to provide a concise summary and overview.
Target Audience:
- Readers interested in the underlying implementation mechanisms of coroutines.
- Users looking to hack/optimize performance by leveraging low-level implementation details.
- Readers interested in coroutine overhead.
- Compiler engineers or readers interested in compiler implementations and potential optimization opportunities.
Since there are already many articles explaining coroutines as of 2026, and covering everything from scratch would make this post excessively long, we will skip the basic introduction to C++20 Coroutines.
By convention, this article may use “Clang” and “compiler” interchangeably when referring to Clang/LLVM. When referring to other compilers, specific names like “GCC” will be used.
Clang/LLVM’s Implementation Choice for Coroutines
Compilers can generally be divided into:
- Frontend: Language-specific parts.
- Middle-end (Mid-end): Language-agnostic and architecture-agnostic parts. Primarily responsible for reusable optimizations.
- Backend: Architecture-specific parts.
Most language features are implemented exclusively in the frontend. Compiler engineers in the C++ committee are mostly frontend engineers (based on impression, not rigorous statistical verification). When implementing language features, frontend engineers naturally choose to implement them in the frontend. This is understandable.
However, when Clang implemented the Coroutines TS, Gor Nishanov keenly observed that implementing C++20 Coroutines in the middle-end could significantly enhance their performance potential.
One of my favorite examples is: https://godbolt.org/z/ad9TjqGan:
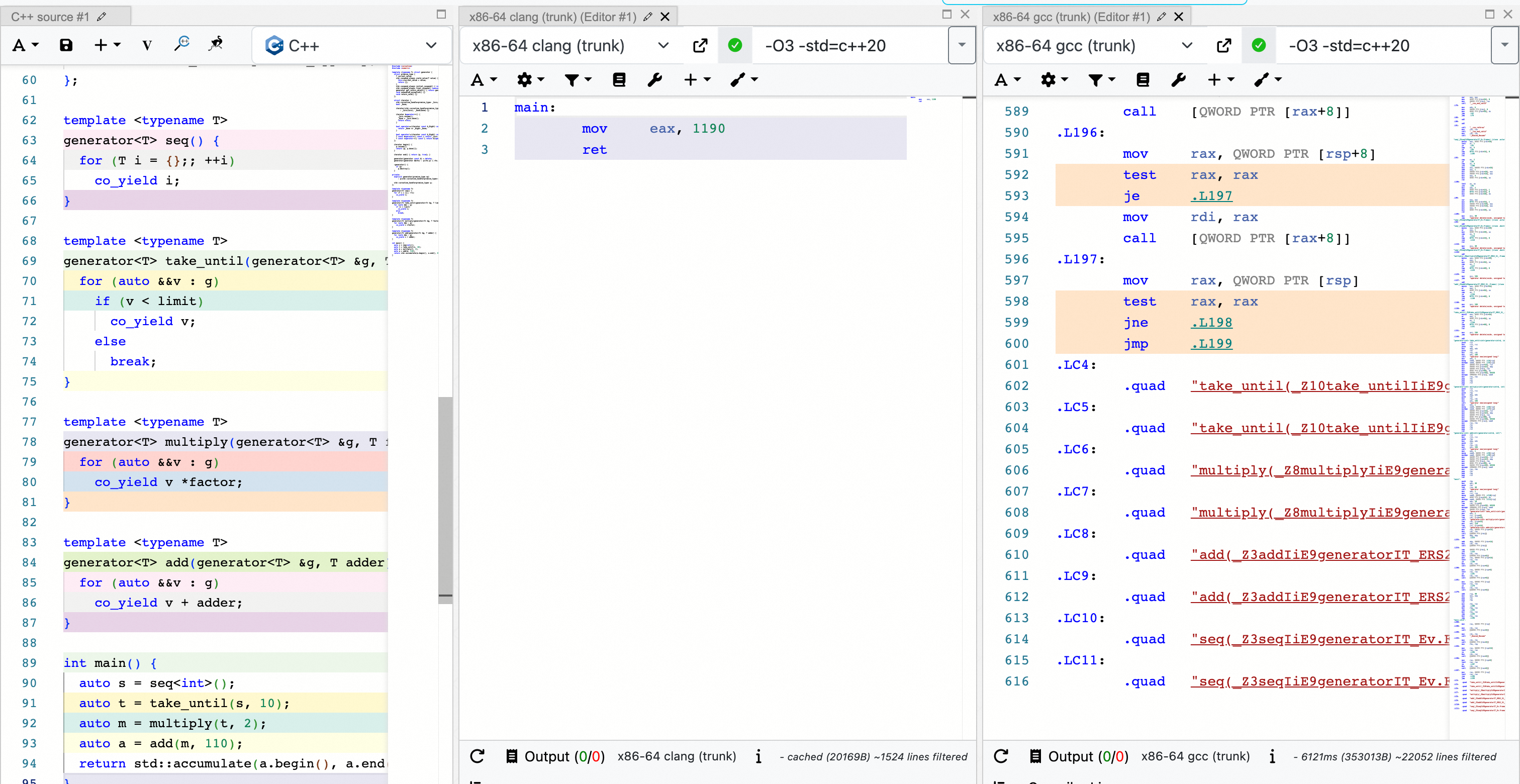
Here, approximately 100 lines of C++20 coroutine code are optimized down to just 3 lines of assembly by Clang. In contrast, GCC, even with -O3 optimization enabled, generates over 600 lines of code.
While this example might be extreme, in production environments, we have also observed that code generated by Clang for C++20 coroutines is significantly superior to that generated by GCC. For one of our coroutine-heavy applications, using Clang resulted in an approximate 20% end-to-end performance improvement compared to GCC. In traditional compilation contexts, this is a very significant gain.
There has long been a prevailing notion that GCC produces better-performing binaries than Clang. (I personally disagree with this broad statement, but that’s a discussion for another time.) The case of C++20 Coroutines demonstrates that for new language features, GCC does not always outperform Clang, even in runtime performance. I believe that middle-end optimizations coordinated with language semantics could be a very promising direction, though that is a broader topic.
The primary reason for the performance difference between GCC and Clang in C++20 coroutines is that GCC implements coroutines in the frontend, whereas Clang implements them through frontend-middle-end coordination.
Compiler support for C++20 coroutines involves two key aspects:
- Generation of the coroutine frame.
- Splitting of the coroutine function.
C++20 coroutines are stackless coroutines—functions that can be suspended. To support suspendable functions, we need to save the intermediate state when the function suspends. This intermediate state is the coroutine frame.
The critical difference between frontend and middle-end implementation lies in when the coroutine frame is generated: before optimizations occur (frontend) or after optimizations occur (middle-end).
Consider this constructed case:
#include <coroutine>
#include <iostream>
#include <cstdlib>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() {}
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
};
[[clang::noinline]]
Task my_coro() {
co_await std::suspend_always{};
co_return;
}
int main() {
auto t = my_coro();
while (!t.done())
t.handle.resume();
return 0;
}
In this case, we record the size of the coroutine frame allocation in Task::promise_type::operator new to observe compiler optimizations. Note that [[clang::noinline]] is used in my_coro() to disable Clang optimizations; otherwise, we wouldn’t see anything. GCC does not recognize [[clang::noinline]].
Running the above code yields:
Clang:
Coroutine allocated 24 bytes
GCC:
Coroutine allocated 32 bytes
This discrepancy likely arises because GCC saves std::suspend_always{} onto the coroutine frame, resulting in a larger frame.
We can construct even more exaggerated examples to make the contrast more intuitive:
... same as above
[[clang::noinline]]
Task my_coro() {
int unused_big_struct[4000];
co_await std::suspend_always{};
co_return;
}
... same as above
Clang:
Coroutine allocated 24 bytes
GCC:
Coroutine allocated 16032 bytes
This example might seem contrived. However, equivalent cases can appear in practice after compiler optimizations:
... same as above
[[clang::noinline]]
void produce_and_consume(int *buffer) {}
bool optimizable_bool_function() { return false; }
[[clang::noinline]]
Task my_coro() {
int big_struct[4000];
if (optimizable_bool_function()) {
produce_and_consume(big_struct);
}
co_await std::suspend_always{};
co_return;
}
... same as above
This produces the same result as the previous example.
In short, a strictly incorrect but not entirely wrong conclusion might be that coroutine functions in GCC receive almost no optimization. Based on this, it is easy to construct examples where Clang drastically outperforms GCC. Claiming that Clang is “N times faster” than GCC for coroutines based on these examples isn’t practically meaningful, as GCC and Clang are effectively operating in different dimensions regarding coroutine optimization. The main point here is that Clang/LLVM’s decision to implement coroutines in the middle-end was extremely correct and forward-thinking.
Of course, there is no free lunch. This decision involves trade-offs:
- Ideally, the LLVM middle-end should be language-agnostic. Implementing part of the C++20 coroutine semantics in the middle-end can be considered a form of “false layering” in design. Specifically, it has drawbacks in two directions:
- To allow the middle-end to perform optimizations and correct handling, we need to continuously expose interfaces in LLVM to accept information from the Clang side.
- We completely lose information about middle-end optimization results in the frontend (which is natural), preventing further operations or designs in the frontend that depend on such information. Simply put, this decision shrinks the design space for coroutines at the C++ language level.
Regarding the first point, a concrete example is the debuggability of C++20 coroutines. Debug info for other language constructs is generated alongside code generation in the frontend; the middle-end only needs to handle these Debug Info IRs. For coroutines, however, since compilation is not complete when the Clang frontend generates code, the Debug Info generated by the frontend does not match the actual coroutine code. This affects the debuggability of Clang-generated C++20 coroutines. Although we later mitigated this by generating Debug Info during coroutine transformation in the LLVM middle-end (interested readers can check Debugging C++ Coroutines), the debuggability of optimized C++20 coroutines in Clang is certainly inferior to GCC, simply because GCC doesn’t optimize coroutines. Beyond debuggability, other issues arise mainly due to the lack of information in the middle-end, leading to occasional bugs, though their impact on users in 2026 is relatively limited.
Regarding the second point, readers interested in language design may feel this more strongly. Those wishing to further design/enhance coroutines often find themselves constrained when dealing with coroutine frames, as the frontend/language has little to no knowledge of the specific composition of the coroutine frame, having delegated it entirely to the compiler’s middle-end. Forcing new constraints almost always leads to worse code generation in some scenarios, as we will attempt to illustrate with a specific example in later sections.
Note: Another reason LLVM chose to implement coroutines in the middle-end is that coroutine semantics might be reusable across other languages. Subsequently, Swift coroutines and one of MLIR’s dialects were implemented based on LLVM Coroutines capabilities.
Coroutine Frame Generation & Tips for Reducing Frame Size
Clang’s algorithm for generating coroutine frames roughly involves checking every local variable, temporary variable, and parameter to determine if its lifetime crosses any suspend points. If it does, it is placed in the coroutine frame; otherwise, it is not. In practice, due to optimizations, many source-level local variables and parameters may be optimized away, making the coroutine frame smaller than the sum of all locals, temporaries, and parameters in the source code.
It is worth noting that currently, the compiler’s middle-end relies on lifetime information output by the frontend. The middle-end uses this lifetime information for optimization but does not currently optimize the lifetime information itself.
Using the previous example:
... same as above
void produce(int *arr) {
for (int i = 0; i < 500; ++i)
arr[i] = i * 2;
}
void consume(int *arr) {
long sum = 0;
for (int i = 0; i < 500; ++i)
sum += arr[i];
// Necessary to ensure these codes won't be optimized out.
std::cout << "Sum: " << sum << "\n";
}
[[clang::noinline]]
Task my_coro() {
int arrays[500];
produce(arrays);
consume(arrays);
co_await std::suspend_always{};
co_return;
}
... same as above
Intuitively, one might think arrays should not be placed in the coroutine frame. However, runtime output shows:
Coroutine allocated 2032 bytes
The reason is that the lifetime information generated by the frontend is essentially annotated around the braces ({}) of its declaration scope, i.e.:
// fake IR
Task my_coro() {
int arrays[500];
lifetime_start(&arrays);
produce(arrays);
consume(arrays);
co_await std::suspend_always{};
lifetime_end(&arrays);
co_return;
}
Thus, the middle-end places arrays in the coroutine frame, even though from a “God’s eye view,” we know this is unnecessary.
Programmer Optimization Hacker Tips
Once programmers understand this phenomenon, they can try manually adding braces ({}) to provide more accurate lifetime information to the compiler:
[[clang::noinline]]
Task my_coro() {
{
int arrays[500];
produce(arrays);
consume(arrays);
}
co_await std::suspend_always{};
co_return;
}
Now the runtime output is:
Coroutine allocated 24 bytes
Due to the complexity of lifetime analysis, middle-end optimizations often fail to fully optimize more complex cases. I believe that even if optimizations to shorten lifetimes are added to the middle-end, this manual optimization will remain effective for many non-trivial cases.
Compiler Optimization Opportunities
Conversely, this presents an opportunity for compilers. We could attempt to add optimizations/transformations in the middle-end to shorten lifetime information. We could search for every use site of each variable and determine if lifetime_end can be moved earlier. A key consideration here is variable escape. When a variable escapes, the middle-end can no longer make further assumptions about its lifetime; in such cases, we must strictly follow the frontend’s guidance.
Lifetime-Independent Optimizations
When the middle-end detects that two variables have completely non-overlapping lifetimes, even if both need to be placed in the coroutine frame, the compiler can make them share the same memory address:
[[clang::noinline]]
Task my_coro(bool cond) {
if (cond) {
int big_struct[500];
produce(big_struct);
co_await std::suspend_always{};
consume(big_struct);
} else {
int big_struct[500];
produce(big_struct);
co_await std::suspend_always{};
consume(big_struct);
}
co_return;
}
Runtime output:
Coroutine allocated 2032 bytes
As seen, the variables in the two branches share the same memory address.
HALO & CoroElide
HALO, or coroutine Heap Allocation eLision Optimization, refers to the compiler eliminating dynamic allocations for coroutines through optimization. The opening example is an application of HALO.
Although HALO is widely known, it is technically a compiler optimization feature, not a language feature. This means a programmer cannot write HALO-friendly code solely by reading the Language Spec. The only way for a programmer to guarantee HALO is to constantly test against different compiler versions.
In LLVM, HALO is called CoroElide. I find “CoroElide” easier to understand, so I use this term, even though HALO sounds cooler.
Conditions for Automatic CoroElide & Application Tips
This section attempts to describe the conditions under which the compiler automatically implements CoroElide without diving deep into implementation details, outlining current limitations.
In short, the condition for automatic CoroElide is: The compiler must prove that the coroutine frame’s lifetime is confined within the scope of the call site. That is, the frame is created upon entering the scope and destroyed before exiting it.
Let’s look at a positive example:
#include <coroutine>
#include <iostream>
#include <cstdlib>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_value(int v) { value = v; }
void unhandled_exception() {}
int value = 0;
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
void resume() {
if (handle)
handle.resume();
}
void destroy() {
if (handle)
handle.destroy();
}
int value() {
if (handle)
return handle.promise().value;
return 0;
}
};
Task foo() {
co_return 43;
}
Task bar() {
auto f = foo();
while (!f.done())
f.resume();
int value = f.value();
f.destroy();
co_return value;
}
int main() {
auto b = bar();
while (!b.done())
b.resume();
std::cout << b.value() << std::endl;
b.destroy();
return 0;
}
Compiling and running this case yields:
43
Notice that the dynamic allocations for both coroutine instances f = foo() and b = bar() were successfully optimized away by the compiler. In bar(), the compiler can clearly see that f’s frame is created at auto f = foo(); and destroyed at f.destroy(). Thus, f’s lifetime is confined within bar()’s scope. The process for b = bar() in main is similar.
However, this syntax is clearly unacceptable in slightly more complex cases. Let’s refactor this case to make Task an awaiter and use symmetric transfer:
#include <coroutine>
#include <iostream>
#include <cstdlib>
#include <future>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
struct FinalAwaiter {
bool await_ready() noexcept { return false; }
std::coroutine_handle<> await_suspend(std::coroutine_handle<> h) noexcept {
if (continuation)
return continuation;
return std::noop_coroutine();
}
void await_resume() noexcept {}
std::coroutine_handle<> continuation;
};
FinalAwaiter final_suspend() noexcept { return {continuation}; }
void return_value(int v) { value = v; }
void unhandled_exception() {}
int value = 0;
std::coroutine_handle<> continuation;
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
bool await_ready() { return false; }
template <class Promise>
auto await_suspend(const std::coroutine_handle<Promise> &h) {
handle.promise().continuation = h;
return handle;
}
int await_resume() {
int value = handle.promise().value;
handle.destroy();
handle = nullptr;
return value;
}
};
int syncAwait(Task &&t) {
std::promise<int> p;
std::future<int> f = p.get_future();
auto lambda = [](std::promise<int> p, Task &&t) -> Task {
p.set_value(co_await t);
co_return 0;
};
auto h = lambda(std::move(p), std::move(t));
while (!h.done()) h.handle.resume();
h.handle.destroy();
return f.get();
}
Task foo() {
co_return 43;
}
Task bar() {
co_return co_await foo();
}
int main() {
std::cout << syncAwait(bar()) << std::endl;
return 0;
}
Compiling with Clang >= 18 yields:
Coroutine allocated 48 bytes
Coroutine allocated 48 bytes
43
Two coroutine memory allocations were not optimized! (The lambda coroutine in syncAwait was optimized, confirmed via assembly.)
If we compile with Clang <= 17, the output becomes:
Coroutine allocated 96 bytes
43
Memory allocation happened only once! The foo() coroutine instance in bar() was optimized into a local variable within bar(), which was then placed into bar()’s coroutine frame. This increased bar()’s frame size but reduced the number of allocations, which is expected. main couldn’t optimize bar()’s allocation because bar()’s completion signal resides in the lambda within syncAwait(), which is too complex for the compiler. From a compiler implementer’s perspective, this is expected behavior, even if we humans can see the optimization potential.
So, what changed between Clang 17 and 18? Since Clang 18, to mimic the standard’s description that await_suspend executes after the coroutine is suspended, await_suspend is no longer inlined (more details below).
For Clang >= 18, the bar() code, after inline optimization, is equivalent to:
Task bar() {
Task f;
f.handle = Task::promise_type::operator new(96); // #1
/* Initialize f.handle, ignored */
// f.await_ready() is always optimized to false
f.await_suspend(current_coroutine_handle()); // await_suspend is NOT inlined
// f.await_resume
int value = f.handle.promise().value;
f.handle.destroy(); // #2
f.handle = nullptr;
// co_return
current_promise.value = value;
return;
}
Here, #1 creates the foo() frame, and #2 destroys it. To a human, it’s obvious that foo()’s lifetime is confined to bar(). But for the compiler, since f.await_suspend is not inlined, it must assume that f.await_suspend might contain code like:
auto Task::await_suspend(std::coroutine_handle) {
...
another_handle = this->handle; // Not caring where another_handle comes from
this->handle = another_handle2; // this->handle changed!
...
}
If f.await_suspend contains such code, #2 no longer destroys the frame created in #1. Consequently, the frame from #1 is not destroyed within bar(), and the compiler cannot prove that foo()’s lifetime is confined to bar().
What can we do?
- Use attributes to let programmers explicitly mark elidable coroutines (discussed later).
- Understand compiler alias analysis to help prove lifetime confinement.
Let’s describe the second method:
#include <coroutine>
#include <iostream>
#include <cstdlib>
#include <future>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
struct FinalAwaiter {
bool await_ready() noexcept { return false; }
std::coroutine_handle<> await_suspend(std::coroutine_handle<> h) noexcept {
if (continuation)
return continuation;
return std::noop_coroutine();
}
void await_resume() noexcept {}
std::coroutine_handle<> continuation;
};
FinalAwaiter final_suspend() noexcept { return {continuation}; }
void return_value(int v) { value = v; }
void unhandled_exception() {}
int value = 0;
std::coroutine_handle<> continuation;
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
auto operator co_await() {
return Awaiter{handle};
}
struct Awaiter {
std::coroutine_handle<promise_type> handle;
bool await_ready() { return false; }
template <class Promise>
auto await_suspend(const std::coroutine_handle<Promise> &h) {
handle.promise().continuation = h;
return handle;
}
int await_resume() {
int value = handle.promise().value;
// handle.destroy();
handle = nullptr;
return value;
}
};
};
int syncAwait(Task &&t) {
std::promise<int> p;
std::future<int> f = p.get_future();
auto lambda = [](std::promise<int> p, Task &&t) -> Task {
p.set_value(co_await t);
co_return 0;
};
auto h = lambda(std::move(p), std::move(t));
while (!h.done()) h.handle.resume();
h.handle.destroy();
return f.get();
}
Task foo() {
co_return 43;
}
Task bar() {
auto f = foo();
int v = co_await f;
f.handle.destroy();
co_return v;
}
int main() {
std::cout << syncAwait(bar()) << std::endl;
return 0;
}
Compiling and running with Clang >= 18 yields:
Coroutine allocated 96 bytes
43
The main difference lies in the Task awaiter implementation:
auto operator co_await() {
return Awaiter{handle};
}
struct Awaiter {
std::coroutine_handle<promise_type> handle;
bool await_ready() { return false; }
template <class Promise>
auto await_suspend(const std::coroutine_handle<Promise> &h) {
handle.promise().continuation = h;
return handle;
}
int await_resume() {
return handle.promise().value;
// handle.destroy();
// handle = nullptr;
return value;
}
};
Now, bar() is equivalent to:
Task bar() {
Task f;
f.handle = Task::promise_type::operator new(96); // #1
/* Initialize f.handle, ignored */
Task::Awaiter awaiter{f.handle}; // Copy construction
// awaiter.await_ready() is always optimized to false
awaiter.await_suspend(current_coroutine_handle()); // await_suspend is NOT inlined
// awaiter.await_resume
int value = awaiter.handle.promise().value;
// f.~Task()
// The compiler can analyze that f.handle is definitely not null.
f.handle.destroy(); // #2
// co_return
current_promise.value = value;
return;
}
Since awaiter only holds a copy of f.handle, and the addresses of f and f.handle are not leaked in any way, the compiler can determine that regardless of awaiter.await_suspend’s implementation, f.handle at #2 necessarily points to the same coroutine instance as f.handle at #1. Thus, the compiler can successfully optimize foo()’s dynamic allocation in bar() into a local variable!
Compiler Optimization Opportunity
The compiler could provide a function or member variable attribute allowing programmers to hint that await_suspend will not modify this->handle (except setting it to nullptr), thereby enabling CoroElide more broadly.
[[clang::coro_await_elidable]]
To facilitate library authors in applying coro elide optimization, Clang introduced the class attribute [[clang::coro_await_elidable]]. Its semantics are: If the return value of a coroutine function of this type is immediately co_awaited, the programmer guarantees to the compiler that the corresponding coroutine instance is elidable.
Example:
class [[clang::coro_await_elidable]] Task { ... };
Task foo();
Task bar() {
co_await foo(); // foo()'s coroutine frame on this line is elidable
auto t = foo(); // foo()'s coroutine frame on this line is NOT elidable
co_await t;
}
In bar(), the first line co_await foo(); immediately awaits the return value, so the compiler considers it elidable. The second line t = foo() does not immediately await, so it doesn’t meet the requirement.
The concept of “immediately co_awaited” might seem strange to users. This is primarily due to implementation difficulties. Performing data flow analysis on the frontend AST is hard, so as a compromise, we chose the “immediately co_awaited” rule, which is easier to implement and understand.
Compiler Optimization Opportunity
While difficult, frontend data flow analysis is not impossible. If we can determine in the frontend whether a coroutine instance is always co_awaited, we could extend the semantics of this attribute. Additionally, clang-tidy checks could become more flexible. Currently, cppcoreguidelines-avoid-capturing-lambda-coroutines forbids any captures in coroutine lambdas, which is overly strict; if we can guarantee they are always co_awaited, many captures would be safe.
[[clang::coro_await_elidable_argument]]
The [[clang::coro_await_elidable_argument]] attribute is an extension primarily for when_all semantics, aiming to allow coroutines like foo(), bar(), zoo() in co_await when_all(foo(), bar(), zoo()) to be optimized by CoroElide.
Usage:
template <typename T>
class [[clang::coro_await_elidable]] Task { ... };
template <typename... T>
class [[clang::coro_await_elidable]] WhenAll { ... };
// `when_all` is a utility function that composes coroutines. It does not
// need to be a coroutine to propagate.
template <typename... T>
WhenAll<T...> when_all([[clang::coro_await_elidable_argument]] Task<T> tasks...);
Task<int> foo();
Task<int> bar();
Task<void> example1() {
// `when_all`, `foo`, and `bar` are all elide safe because `when_all` is
// under a safe elide context and, thanks to the [[clang::coro_await_elidable_argument]]
// attribute, such context is propagated to foo and bar.
co_await when_all(foo(), bar());
}
Task<void> example2() {
// `when_all` and `bar` are elide safe. `foo` is not elide safe.
auto f = foo();
co_await when_all(f, bar());
}
Task<void> example3() {
// None of the calls are elide safe.
auto t = when_all(foo(), bar());
co_await t;
}
Is Coro Eliding Always an Optimization?
Background Story
We extensively enhanced CoroElide capabilities internally early on, expecting positive performance gains from reduced memory allocations. However, in every performance test, we observed performance regressions in most cases rather than improvements.
Analysis
Memory Usage
In practice, coroutines are often tied to asynchronous high-concurrency programming. For the entry point of an async chain, dynamic allocation is always required:
Task zoo() {
something
}
Task foo() {
...
co_await zoo();
...
}
Task bar() {
...
co_await foo();
...
}
void entry() {
bar().start(callback); // This is a non-blocking call! We MUST dynamically allocate
...
}
If foo() and zoo() frames are elided, the memory allocated in entry looks like this:
┌─────────────────────────────────────────┐
│ bar() Coroutine Frame │
│ ┌───────────────────────────────────┐ │
│ │ foo() Coroutine Frame │ │
│ │ ┌─────────────────────────────┐ │ │
│ │ │ zoo() Coroutine Frame │ │ │
│ │ │ Params/Locals + State │ │ │
│ │ └─────────────────────────────┘ │ │
│ │ │ │
│ │ Params/Locals + State │ │
│ └───────────────────────────────────┘ │
│ │
│ Params/Locals + State │
└─────────────────────────────────────────┘
We must allocate sizeof(bar's self states) + sizeof(foo's self states) + sizeof(zoo's self states) at once.
If foo() and zoo() frames are dynamically allocated on demand, actual memory usage decreases before foo()/zoo() execute or after they finish:
Memory
▲ ┌────────────────────────────────────────────────────────────┐
│ │█████████████████████████████ bar + foo + zoo ██████████████│
│ │████████████████████████████████████████████████████████████│
│ │████████████████████████████████████████████████████████████│
│ │████████████████████████████████████████████████████████████│
└──┴────────────────────────────────────────────────────────────┴──▶ time
bar.start bar.end
Memory
▲ ┌────────────────────────────────────────────────────────────┐
│ │ ███████████████████ │
│ │ ███████████████████ │
│ │ ███████████████████████████████████████ │
│ │████████████████████████████████████████████████████████████│
└──┴────────────────────────────────────────────────────────────┴──▶ time
bar.start foo.start() zoo.start zoo.end foo.end bar.end
As the coroutine chain grows, elision might lead to higher memory peaks and sustained high memory usage.
Compiler Optimization Opportunity
Profiling information might need new dimensions to help the compiler judge coroutine instance lifetime length. For long-lived instances, elision helps; for short-lived ones, we might prefer not to elide. Coroutine frame size should also be a factor.
Hot/Cold Path Information
Another issue with LLVM’s CoroElide was that it performed the “optimization” whenever conditions were met at compile time, which isn’t always beneficial.
Example:
Task foo() { ... }
Task bar(bool cond) {
if (cond) {
...
co_await foo();
...
}
...
}
If cond is almost always false in practice, optimizing co_await foo() via CoroElide is a negative optimization. It only increases bar()’s frame size with no benefit.
In Clang 22, we added hot/cold path judgment to CoroElide. Without profiling info, static analysis is used: loops are considered hot, if blocks outside loops are considered cold, and CoroElide is skipped for cold paths.
Compiler Optimization Opportunity
Currently, hot/cold judgment is only enabled when using [[clang::coro_await_elidable_argument]]. It is not yet applied to automatic CoroElide that doesn’t rely on programmer annotations.
General Limitations of CoroElide & Standardization
Besides the mentioned limitations, a major restriction is that the compiler must see the body of the elided coroutine at compile time to calculate its frame size and convert it to a local variable.
Currently, this is achieved via inlining. Future cross-function analysis might help. However, in the current single-process, single-file compilation model, the compiler cannot access coroutine implementations in other unreachable translation units (TUs), preventing elision.
While Cross-TU analysis or LTO could theoretically achieve this, these limitations make it difficult to push CoroElide-related features in the C++ Standard Committee.
Language-Coordinated Coroutine Memory Allocation Optimization Schemes
Explicit Coroutine Frame Type with Frontend-Opaque Upper Bound
Proposed by Lewis Baker. The idea is for the compiler frontend to calculate an upper bound for the coroutine frame size, allowing pre-allocation. Programmers can then use this pre-allocated memory as the coroutine frame space without changing the function signature.
Example:
Task foo(...) { ... }
Task bar(...) { ... }
...
auto frame = decl_coro_frame_type(bar(a, b, c));
auto t = call_coro_with_specified_frame(bar(a, b, c), frame);
auto size = get_coro_frame_size_uplimit(foo(a, b, c));
void *buffer = personalized_allocator(size);
auto f = call_coro_with_specified_frame(foo(a, b, c), buffer);
This approach is feasible but has drawbacks:
- Still requires the coroutine implementation to be visible in the current TU.
- Requires disabling current CoroElide optimizations; otherwise, the upper bound is meaningless (as CoroElide can cause frame bloat, as discussed in the memory usage section).
- For Clang/LLVM (middle-end implementation), this frontend-calculated upper bound might be much larger than actually needed (see the Clang vs. GCC section), potentially causing negative optimization for users.
Points 2 and 3 illustrate how Clang/LLVM’s implementation choice restricts the language design space for coroutines.
Coroutine Elided Allocation Hook && Stacked Allocation
Idea source: MicroCai, https://github.com/alibaba/async_simple/discussions/398
The idea is to provide new allocation/deallocation interfaces in the promise_type. When the compiler decides to elide, instead of blindly converting the frame to a local variable, it uses these interfaces. The clever part is that these allocators can use efficient stack-based memory allocers. Allocation simply increments the stack pointer (with fallback if space is insufficient).
Drawbacks:
- Assumes elided coroutine instances are constructed and destructed in order. This assumption is stronger than current CoroElide requirements. For example, in
when_allscenarios, applying this design directly is risky. - Targets only classic
Task-type coroutines. While C++20 allows strong extensibility, this design targets a specific (albeit mainstream) type.
Advantages over static CoroElide:
- Avoids hot/cold path issues.
- Uses efficient local stacked allocation, avoiding inefficient global allocation.
- Avoids excessive memory overhead from premature large allocations.
I have implemented a draft in the compiler: https://github.com/ChuanqiXu9/llvm-project/tree/StackedAllocation
Library implementation: https://github.com/alibaba/async_simple/commit/a13f69eb408fb7e7ce25ca1f75f42e84931ab711
Interested users can try this branch or test the implementation in their own coroutine libraries. I plan to test this on large-scale applications soon.
Summary
CoroElide is the most famous coroutine optimization. Due to the complexity of dynamic allocation, statically determining the best memory allocation strategy is difficult. Long-term, there is significant room for improvement in compilers, libraries, and compiler-library coordination.
- Automatic CoroElide: Due to changes in
await_suspend, many previously elidable codes are no longer automatically elidable in Clang 18+. Extra hacks are needed to write elide-friendly code. Compilers should provide attributes to let users inform the compiler thatawait_suspendwon’t modifythis->handle. - Deterministic Elide: Clang’s newer versions provide
[[clang::coro_await_elidable]]for deterministic elide opportunities. However, due to frontend architecture, it only works for immediately awaited objects. Future frontends need stronger data flow analysis or rely on middle-end automatic elide capabilities. - Static CoroElide isn’t always optimal: There are opportunities for profiling-based optimizations or allowing users to provide high-level hints.
- Compiler-Library Coordination: Significant potential exists here.
noexcept
Background Story
When coroutines first entered the standard, we began adopting them. Given primitive compiler/library support and difficult-to-debug async lifecycle issues, we didn’t switch synchronous paths to async all at once. Instead, we used macros to flexibly switch between coroutine-based sync and async paths.
Comparing coroutine-based sync paths with original sync paths, we found significant performance regression. We quickly identified coroutine allocation as the cause and optimized our library for automatic elision (using an older Clang version). However, significant performance differences remained. The root cause was coroutines being wrapped in try-catch.
Automatic noexcept Propagation
For:
void bar();
[[clang::noinline]] // For readable code generation
void foo() {
try {
bar();
} catch(...) {}
}
void zoo() {
try {
foo();
} catch (...) {
}
}
We would hope the compiler automatically marks foo() as noexcept (in the middle-end), eliminating the useless try-catch in zoo().
However, Clang currently fails to do this:
clang++ -O3 -S -emit-llvm -o - %s
define dso_local void @zoo()() local_unnamed_addr #2 personality ptr @__gxx_personality_v0 !dbg !24 {
invoke void @foo()()
to label %5 unwind label %1, !dbg !25
1:
%2 = landingpad { ptr, i32 }
catch ptr null, !dbg !27
%3 = extractvalue { ptr, i32 } %2, 0, !dbg !27
%4 = tail call ptr @__cxa_begin_catch(ptr %3) #3, !dbg !28
tail call void @__cxa_end_catch(), !dbg !29
br label %5, !dbg !29
5:
ret void, !dbg !31
}
After discussion, this seems to be a “loophole” (unconfirmed) in the language standard, depending on behavior when an exception’s destructor throws.
Example:
struct E {
~E() noexcept(false) {
throw 3;
}
};
void bar() {
throw E();
}
Even if foo() catches all exceptions, the compiler cannot guarantee foo() won’t throw if E’s destructor throws.
The Standard Committee hasn’t concluded on whether exception destructors can throw or what the behavior should be. From Clang’s perspective, we avoid changing existing behavior arbitrarily. However, since throwing exception destructors are rare, we provided -fassume-nothrow-exception-dtor to let users inform the compiler that no exception destructors throw, enabling optimization:
clang++ -O3 -S -emit-llvm -o - %s -fassume-nothrow-exception-dtor
define dso_local void @zoo()() local_unnamed_addr #2 !dbg !24 {
tail call void @foo()(), !dbg !25
ret void, !dbg !27
}
Clear optimization effect.
Relation to Coroutines
How does this relate to coroutines?
Language design guarantees every coroutine is wrapped in try-catch:
{
promise-type promise promise-constructor-arguments ;
try {
co_await promise.initial_suspend() ;
function-body
} catch ( ... ) {
if (!initial-await-resume-called)
throw ;
promise.unhandled_exception() ;
}
final-suspend :
co_await promise.final_suspend() ;
}
final_suspend() is guaranteed not to throw. If the library author guarantees promise.unhandled_exception() doesn’t throw, and co_await promise.initial_suspend() (and prior steps like frame allocation/promise construction) don’t throw, then the entire coroutine type can be considered noexcept. Combined with -fassume-nothrow-exception-dtor, we can automatically add noexcept to every coroutine, triggering more optimizations.
Coro RVO
Coroutines don’t have traditional return statements, but calling a coroutine function still returns an object to the caller via promise_type::get_return_object().
Clang implements RVO for this return, constructing the coroutine directly in the caller’s return slot to avoid repeated construction/passing overhead.
However, due to implementation limitations, RVO in coroutines is currently only enabled when the coroutine return type matches the type returned by promise_type::get_return_object().
await_suspend Execution Happens After Coroutine Suspension
The standard states:
[expr.await]p5.1 If the result of await-ready is false, the coroutine is considered suspended.
This means when await_suspend() executes, the containing coroutine is already suspended (stopped).
Previously, compiler-generated code executed await_suspend() within the containing coroutine, deciding whether to continue or suspend (return) based on the result after execution. This was for performance: allowing await_suspend() inlining and avoiding actual stack out/in if execution continues.
However, we found several related bugs, most importantly the usage of destroying the coroutine within await_suspend(). Per standard, this is valid because the coroutine is considered suspended. But per previous LLVM implementation, the coroutine was still considered executing.
To fix this, we stopped inlining await_suspend() to mimic the standard wording. This is why automatic elision stopped working in Clang 18.
Note: We are only mimicking the standard wording; await_suspend() is not truly moved outside the coroutine.
initial_suspend != always_suspend Generates More Code and Blocks CoroElide
LLVM currently handles coroutines with initial_suspend other than always_suspend poorly, generating extra code.
LLVM splits a coroutine into three parts:
- Ramp: Handles memory allocation, Promise construction, and frame initialization. Corresponds to the original function.
- Resume: Jumps to different suspend points based on state. Corresponds to
std::coroutine_handle<>::resume(). - Destroy: Destroys the frame. Corresponds to
std::coroutine_handle<>::destroy().
The split between Ramp and Resume is based on the first compile-time determinable suspend point, which is initial_suspend if it is always_suspend. When initial_suspend is always_suspend, the Ramp function is very small and inline-friendly.
Example bar() with always_suspend:
define dso_local void @bar()(ptr dead_on_unwind writable writeonly sret(%struct.Task) align 8 captures(none) initializes((0, 8)) %0) local_unnamed_addr #0 personality ptr @__gxx_personality_v0 {
%2 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, ptr noundef nonnull @.str, i64 noundef 20)
%3 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::ostream& std::ostream::_M_insert<unsigned long>(unsigned long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, i64 noundef 96)
%4 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) %3, ptr noundef nonnull @.str.1, i64 noundef 7)
%5 = tail call noalias noundef nonnull dereferenceable(96) ptr @operator new(unsigned long)(i64 noundef 96) #28
store ptr @bar() (.resume), ptr %5, align 8
%6 = getelementptr inbounds nuw i8, ptr %5, i64 8
store ptr @bar() (.destroy), ptr %6, align 8
%7 = getelementptr inbounds nuw i8, ptr %5, i64 16
store i32 0, ptr %7, align 8
%8 = getelementptr inbounds nuw i8, ptr %5, i64 24
store ptr null, ptr %8, align 8
store ptr %5, ptr %0, align 8
%9 = getelementptr inbounds nuw i8, ptr %5, i64 88
store i2 0, ptr %9, align 8
ret void
}
If we change initial_suspend to suspend_never:
define dso_local void @bar()(ptr dead_on_unwind writable writeonly sret(%struct.Task) align 8 captures(none) initializes((0, 8)) %0) local_unnamed_addr #0 personality ptr @__gxx_personality_v0 {
%2 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, ptr noundef nonnull @.str, i64 noundef 20)
%3 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::ostream& std::ostream::_M_insert<unsigned long>(unsigned long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, i64 noundef 56)
%4 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) %3, ptr noundef nonnull @.str.1, i64 noundef 7)
%5 = tail call noalias noundef nonnull dereferenceable(56) ptr @operator new(unsigned long)(i64 noundef 56) #27
store ptr @bar() (.resume), ptr %5, align 8
%6 = getelementptr inbounds nuw i8, ptr %5, i64 8
store ptr @bar() (.destroy), ptr %6, align 8
%7 = getelementptr inbounds nuw i8, ptr %5, i64 16
store i32 0, ptr %7, align 8
%8 = getelementptr inbounds nuw i8, ptr %5, i64 24
store ptr null, ptr %8, align 8
store ptr %5, ptr %0, align 8
%9 = invoke noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, ptr noundef nonnull @.str, i64 noundef 20)
to label %10 unwind label %25
10:
%11 = invoke noundef nonnull align 8 dereferenceable(8) ptr @std::ostream& std::ostream::_M_insert<unsigned long>(unsigned long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, i64 noundef 48)
to label %12 unwind label %25
12:
%13 = invoke noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) %11, ptr noundef nonnull @.str.1, i64 noundef 7)
to label %14 unwind label %25
14:
%15 = invoke noalias noundef nonnull dereferenceable(48) ptr @operator new(unsigned long)(i64 noundef 48) #27
to label %16 unwind label %25
16:
%17 = getelementptr inbounds nuw i8, ptr %5, i64 40
store ptr %15, ptr %17, align 8
%18 = getelementptr inbounds nuw i8, ptr %15, i64 8
store ptr @foo() (.destroy), ptr %18, align 8
%19 = getelementptr inbounds nuw i8, ptr %15, i64 32
%20 = getelementptr inbounds nuw i8, ptr %15, i64 16
%21 = getelementptr inbounds nuw i8, ptr %15, i64 24
store ptr null, ptr %21, align 8
store i32 43, ptr %20, align 8
store ptr null, ptr %19, align 8
store ptr null, ptr %15, align 8
%22 = getelementptr inbounds nuw i8, ptr %15, i64 40
store i1 false, ptr %22, align 8
%23 = load ptr, ptr @std::__n4861::coroutine_handle<std::__n4861::noop_coroutine_promise>::_S_fr, align 8
invoke fastcc void %23(ptr nonnull @std::__n4861::coroutine_handle<std::__n4861::noop_coroutine_promise>::_S_fr)
to label %24 unwind label %25
24:
unreachable
25:
%26 = landingpad { ptr, i32 }
catch ptr null
%27 = extractvalue { ptr, i32 } %26, 0
%28 = tail call ptr @__cxa_begin_catch(ptr %27) #23
invoke void @__cxa_end_catch()
to label %29 unwind label %36
29:
%30 = getelementptr inbounds nuw i8, ptr %5, i64 32
%31 = load ptr, ptr %8, align 8
store ptr %31, ptr %30, align 8
store ptr null, ptr %5, align 8
%32 = getelementptr inbounds nuw i8, ptr %5, i64 48
store i1 true, ptr %32, align 8
%33 = icmp eq ptr %31, null
%34 = select i1 %33, ptr @std::__n4861::coroutine_handle<std::__n4861::noop_coroutine_promise>::_S_fr, ptr %31
%35 = load ptr, ptr %34, align 8
tail call fastcc void %35(ptr nonnull %34)
ret void
36:
%37 = landingpad { ptr, i32 }
cleanup
tail call void @operator delete(void*, unsigned long)(ptr noundef nonnull %5, i64 noundef 56) #23
resume { ptr, i32 } %37
}
This essentially duplicates the Resume function content into Ramp. Since most coroutine logic is in Resume, duplicating it inflates code size. In large projects, code bloat often leads to performance degradation.
Additionally, larger Ramp functions hinder inlining, which further hinders CoroElide.
Compiler Optimization Opportunity
For coroutines where initial_suspend is not suspend_always, we should consider forcibly inserting a call to the Resume function at the initial_suspend point. This adds one function call but significantly reduces code size and enables CoroElide.
[[clang::coro_only_destroy_when_complete]]
Since coroutines can be destroyed after any suspend point, the destroy function must handle different suspend indices.
Example:
A foo() {
dtor d;
co_await something();
dtor d1;
co_await something();
dtor d2;
co_return 43;
}
Generated destroy function (pseudo-code):
void foo.destroy(foo.Frame *frame) {
switch(frame->suspend_index()) {
case 1: frame->d.~dtor(); break;
case 2: frame->d.~dtor(); frame->d1.~dtor(); break;
case 3: frame->d.~dtor(); frame->d1.~dtor(); frame->d2.~dtor(); break;
default: break;
}
frame->promise.~promise_type();
delete frame;
}
If the library designer knows Coroutine A does not support Cancel semantics (i.e., it is only destroyed upon completion), this code is inefficient. We can add the class attribute [[clang::coro_only_destroy_when_complete]] to convey this. The compiler then generates:
void foo.destroy(foo.Frame *frame) {
frame->promise.~promise_type();
delete frame;
}
Compiler Optimization Opportunity
[[clang::coro_only_destroy_when_complete]]might be too strong, as many libraries support Cancel. We might need call-site or suspend-point level attributes to tell the compiler that a specific suspend will always resume, enabling finer-grained optimization. Example:[[clang::must_resume]] co_await something();- This attribute also implies that every suspend point will eventually be resumed. This information could be used for other optimizations but is currently underutilized.
CIR
CIR (Clang Intermediate Representation) attempts to solve:
- Frontend lack of data flow analysis.
- Middle-end lack of language information.
At first glance, CIR seems ideal for coroutine generation, avoiding the “false layering” issue. However, CIR will likely only perform analysis for coroutines; actual code generation must be delayed to the current coroutine frame generation stage. This is because LLVM generates coroutine frames late to maximize middle-end optimization benefits. Moving code generation earlier would almost certainly cause performance regression.
Nevertheless, CIR should help coroutine performance. By analyzing at the CIR level, we can insert more optimization hints to guide LLVM in optimizing coroutine code.
Conclusion
For Users:
- Use Clang for significant performance gains.
- Use
{}to refine variable lifetimes to shrink coroutine frames. - Enable
-fassume-nothrow-exception-dtorif your codebase has no throwing exception destructors. - Keep coroutine return types consistent with
get_return_object.
For Coroutine Library Authors:
- Write CoroElide-friendly code (avoid escaping
thisandthis->handle). - CoroElide isn’t always an optimization, but there’s room for improvement.
- Try stacked allocation.
- If coroutines aren’t cancellable, use
[[clang::coro_only_destroy_when_complete]]. - Prefer
std::suspend_alwaysforinitial_suspend.
For Compiler Developers:
- Consider shrinking coroutine local variable lifetime information (watch out for escape analysis).
- Profiling-based coroutine optimizations are promising (e.g., CoroElide with profiling).
- Many opportunities exist for coordination with the language frontend, allowing users to provide more information for further optimization.