C++20 Coroutines 编译器视角下的优化机会
- Clang/LLVM 对协程的实现选择
- 协程帧的生成 & 缩减协程帧的 tips
- HALO & CoroElide
- noexcept
- Coro RVO
- await_suspend 的运行发生在协程暂停之后
- initial_suspend 不为 always_suspend 会生成较多代码且 block CoroElide 优化
- [[clang::coro_only_destroy_when_complete]]
- CIR
- 总结
在 2026 年,C++20 Coroutines 已经不是一个新东西了。 不过从编译器视角出发的 C++20 Coroutines 的文章还比较少,在这里做一个简单的总结和梳理。
可能感兴趣的读者:
- 对协程底层实现机制感兴趣的读者。
- 想通过底层实现机制,使用 hack 优化性能的用户。
- 对协程 overhead 感兴趣的读者。
- 对编译器实现感兴趣,想看下潜在编译优化机会的读者或编译器工程师。
因为 2026 年解析协程的文章已经很多了,再加上从头说起的话篇幅过长,本文会跳过对 C++20 Coroutines 基础的介绍。
出于习惯,本文对 Clang 和编译器两个词可能会不加区分的使用,指代其他编译器时会使用 GCC 等词专门指代。
Clang/LLVM 对协程的实现选择
编译器可以简单地分为:
- 前端:语言相关的部分。
- 中端:语言无关架构无关的部分。主要是各种可复用的优化。
- 后端:架构相关的部分。
大多数语言 feature 基本都会在且只在前端完成。C++ 委员会里的编译器工程师也基本为编译器前端工程师(印象里是这样的,没有真正统计、验证过)。当前端工程师实现语言特性时,会自然而然的选择在前端完成该特性的实现。这当然无可厚非。
然而当 Clang 实现 Coroutines TS 时,Gor Nishanov 敏锐地发现在中端实现 C++20 Coroutines 可以极大程度地提升 C++20 Coroutines 的性能潜力。
一个我最喜欢用的例子是:https://godbolt.org/z/ad9TjqGan:
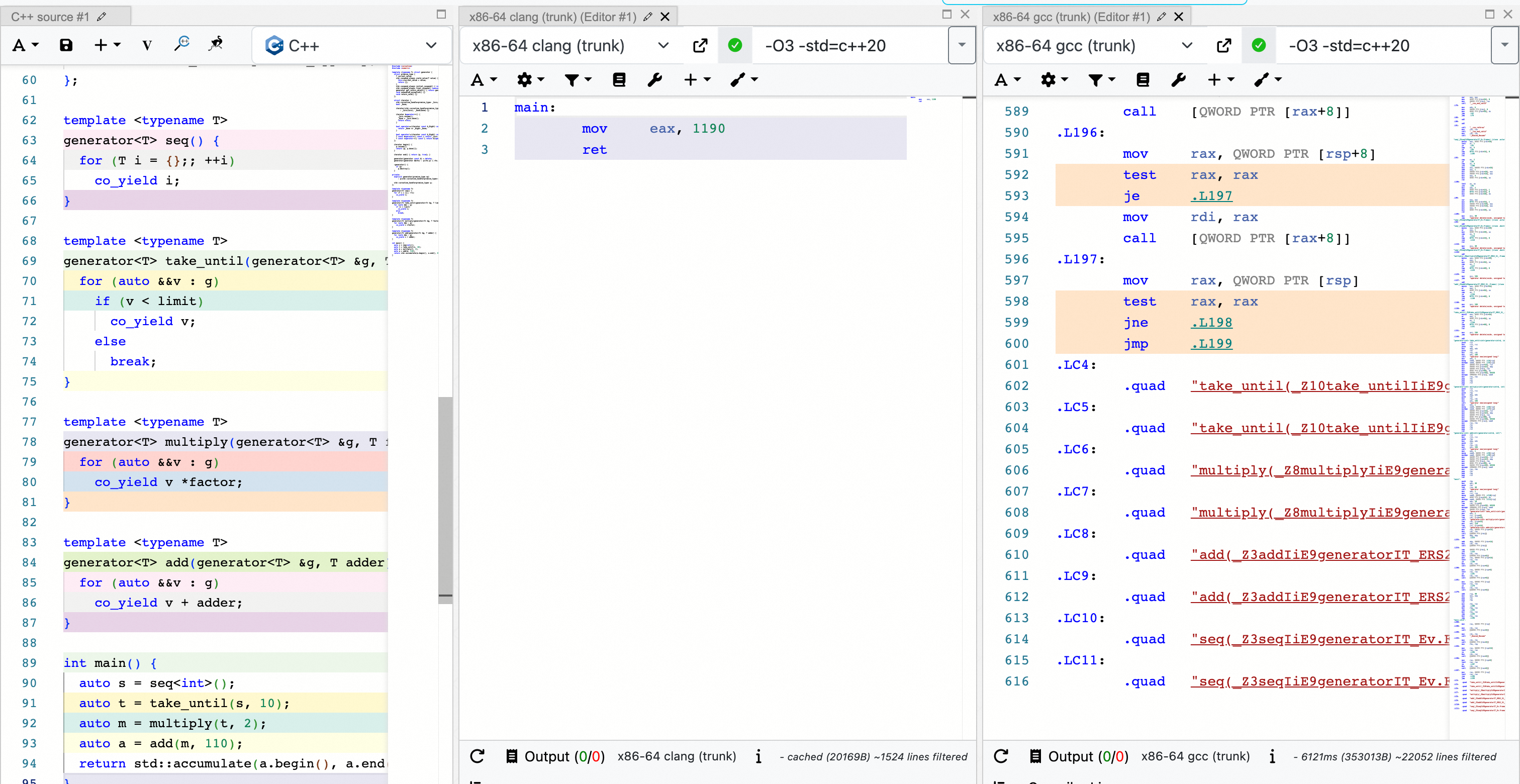
这里约 100 行的 C++20 协程代码在 Clang 编译器中被优化到只有 3 行汇编,而在 GCC 中,同样开启了 O3 优化,却生成了 600 余行代码。
当然这个例子可能过于极端了。但在实际生产中,我们也观察到了在 C++20 协程用 Clang 生成的代码要明显优于 GCC 生成的代码。我们一个 Coroutines Heavy 的应用使用 Clang 编译产物的性能在端到端对比 GCC 编译产物大概会有 20% 提升。在传统编译领域这是非常显著的性能提升了。
长久以来似乎总有说法说,在编译产物性能方面,GCC 总是好于 Clang。(当然单就这句话我也不是很同意,之后可以在其他地方讨论)。而在 C++20 Coroutines 的例子,则说明在新语言特性方面,哪怕在运行时性能方面,GCC 也不会总强于 Clang。我也觉得语言协同的中端优化,可能会是一个非常好的方向,当然这是更大的话题了。
造成 GCC 和 Clang 在 C++20 协程上性能差异的主要原因是,GCC 选择了在前端实现 C++20 协程而 Clang 选择了前端和中端协同实现 C++20 协程。
C++20 协程的编译器支持有两个关键点:
- 协程帧的生成
- 协程函数的切分
C++20 协程是无栈协程,无栈协程是可以被暂停的函数。为了支持可以被暂停的函数,我们需要保存函数暂停时的中间状态。这个中间状态就是协程帧。
而选择在前端实现和在中端实现的关键差别则是,我们是在优化发生之前生成协程帧,还是在优化发生之后生成协程帧。
来一个构造的 case:
#include <coroutine>
#include <iostream>
#include <cstdlib>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() {}
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
};
[[clang::noinline]]
Task my_coro() {
co_await std::suspend_always{};
co_return;
}
int main() {
auto t = my_coro();
while (!t.done())
t.handle.resume();
return 0;
}
case 里我们在 Task::promise_type::operator new 里中记录协程帧分配的大小,用于观察编译器的优化。注意我在 my_coro() 中需要使用 [[clang::noinline]] 禁用 Clang 优化否则我们就什么都看不见了。而 GCC 其实是不认识 [[clang::noinline]] 的。
以上代码直接运行的结果是,
Clang:
Coroutine allocated 24 bytes
GCC:
Coroutine allocated 32 bytes
这里可能是因为 GCC 保存了 std::suspend_always{} 到协程帧上导致了协程帧更大。
这里还可以写一些很傻的例子来让这个对比更直观:
... same as above
[[clang::noinline]]
Task my_coro() {
int unused_big_struct[4000];
co_await std::suspend_always{};
co_return;
}
... same as above
Coroutine allocated 24 bytes
GCC:
Coroutine allocated 16032 bytes
这个例子可能略显做作。但在实践中等价的一些 case 在编译器优化后其实是可能出现的:
... same as above
[[clang::noinline]]
void produce_and_consume(int *buffer) {}
bool optimizable_bool_function() { return false; }
[[clang::noinline]]
Task my_coro() {
int big_struct[4000];
if (optimizable_bool_function()) {
produce_and_consume(big_struct);
}
co_await std::suspend_always{};
co_return;
}
... same as above
这会和上面的例子产生一样的结果。
总之,严格来说不正确但可能不算特别错的一个结论可能是,GCC 下的协程函数基本上不会有什么优化。基于这个结果,专门找一些 Clang 能优化的例子就非常容易构造出 Clang 对比 GCC 的,极具冲击力的优化结果对比。用这些例子说 Clang 在协程上的性能是 GCC 的 N 倍并没有什么实际意义。因为在协程优化这个话题上,GCC 和 Clang 已经在字面意思上不在一个维度了。这里主要想说的是,Clang/LLVM 在实现协程时的决策是极其正确且富有远见的。
当然天下没有免费的午餐,这个决策也有 trade off,具体来说是:
- LLVM 中端理想情况下应该是语言无关的。但在中端实现一部分 C++20 协程语义的决定,在设计上可以说某种程度上是一种 false layering。具体来说,他有两个方向的缺点:
- 为了让中端有更多语言相关信息以完成优化和正确的处理,我们需要在 LLVM 中不断暴露接口,以接受 Clang 侧传来的信息。
- 我们在前端完全失去了中端优化结果的信息(这是当然的),从而让我们无法在前端对涉及到中端优化结果信息的事项做进一步的操作与涉及。简而言之,这个决定缩小了 C++ 在语言层面对协程的设计空间。
对于前者,一个具体的例子是 C++20 协程的 Debuggability。其他语言构造的 Debug info 是编译器在前端生成代码时一齐生成的,中端只需要处理这些 Debug Info IR 即可。而对于协程,因为 Clang 中前端生成代码时协程的编译并没有完成,这使得 Clang 前端生成协程时的 Debug Info 并不能匹配真实的协程代码。导致 Clang 生成的 C++20 协程的 Debuggability 受到了影响。虽然后来我们在 LLVM 中端进行协程转化时生成了 Debug Info 来缓解这一点。对细节感兴趣的读者可以看 Debugging C++ Coroutines 。但开启优化后 C++20 协程的 Debuggability 肯定是比不上 GCC 的,毕竟 GCC 不会优化协程。除了 Debugability 之外,其他的问题更多是因为中端缺乏信息,所以时不时会有新的 bug 出现,当然这点在 2026 年的今天对用户的影响已经比较有限了。
而对于后者,可能对语言设计感兴趣的读者会有更强的感触。希望对协程进行进一步设计/增强的人,在涉及到协程帧相关的事情时,往往会显得局促。因为前端/语言对于协程帧的具体组成基本上是一无所知或者全放权给编译器中端的。强行增加新的约束几乎总会导致编译器在某种情况下生成更差的代码,在本文后面的章节会尝试举一个具体的例子。
注:LLVM 选择在中端实现协程的另一层原因是协程语义可能可以在其他语言上复用。后续 Swift 协程和 MLIR 的一个方言都基于了 LLVM Coroutines 能力实现。
协程帧的生成 & 缩减协程帧的 tips
Clang 生成协程帧的算法大概是,对于每一个局部变量、临时变量以及参数,判断其生命周期是否会跨越 suspend points,如果会,则将其放入协程帧上,反之则不会。实践中,因为优化的原因,许多源代码中的局部变量和参数可能会被优化掉,让协程帧的大小小于源代码中局部变量、临时变量和参数的大小之和。
这里值得注意的一点是,目前编译器中端对于生命周期的判断主要源于前端的输出。而编译器中端目前只会利用生命周期进行优化,而不是优化生命周期本身。
同样使用上面的例子:
... same as above
void produce(int *arr) {
for (int i = 0; i < 500; ++i)
arr[i] = i * 2;
}
void consume(int *arr) {
long sum = 0;
for (int i = 0; i < 500; ++i)
sum += arr[i];
// Necessary to make sure these codes won't be
// optimized out.
std::cout << "Sum: " << sum << "\n";
}
[[clang::noinline]]
Task my_coro() {
int arrays[500];
produce(arrays);
consume(arrays);
co_await std::suspend_always{};
co_return;
}
... same as above
在这个 case 中,我们直观的会认为 arrays 不应该被放入协程帧中。但运行时显示:
Coroutine allocated 2032 bytes
原因是因为前端生成的生命周期信息基本可以认为是在其声明周围的大括号({})附近标注,即:
// fake IR
Task my_coro() {
int arrays[500];
lifetime_start(&arrays);
produce(arrays);
consume(arrays);
co_await std::suspend_always{};
lifetime_end(&arrays);
co_return;
}
所以中端将 arrays 放入协程帧中,哪怕我们在上帝视角知道这并不是必要的。
程序优化 hacker tips
当程序员了解这个现象后,就可以尝试通过手动增加大括号({})为编译器提供更准确的生命周期信息:
[[clang::noinline]]
Task my_coro() {
{
int arrays[500];
produce(arrays);
consume(arrays);
}
co_await std::suspend_always{};
co_return;
}
此时运行时输出为:
Coroutine allocated 24 bytes
同时由于生命周期问题的复杂性,实际上中端优化很可能无法对更复杂的例子做充分的优化。我认为,哪怕在编译器中端新增了缩短生命周期的优化之后,对于大量非 trivial case,这种手动优化依然是有效的。
编译优化机会
反过来说,这对于编译器而言也是另一个机会。我们可以尝试在中端新增优化/转化缩短生命周期信息。我们可以反过来寻找每个变量的每一个使用点,然后判断是否可以将 lifetime_end 的生命周期提前。这里的一个关键点可能是,我们需要非常小心变量逃逸的情况。当变量逃逸时,我们在中端中就不再可以对其生命周期做任何进一步的假设,此时我们唯一能做的就是遵循前端的指导。
生命周期无关优化
当中端发现两个变量的生命周期完全不重叠时,哪怕这两个变量都要被放到协程帧中,编译器可以通过让两个生命周期不重叠的变量共享相同的地址:
[[clang::noinline]]
Task my_coro(bool cond) {
if (cond) {
int big_struct[500];
produce(big_struct);
co_await std::suspend_always{};
consume(big_struct);
} else {
int big_struct[500];
produce(big_struct);
co_await std::suspend_always{};
consume(big_struct);
}
co_return;
}
此时运行输出为:
Coroutine allocated 2032 bytes
可以看到两个分支中的变量共享了相同的内存地址。
HALO & CoroElide
HALO, 即 coroutine Heap Allocation eLision Optimization,指编译器通过优化消除协程动态分配。开头的例子即是 HALO 的一个应用。
虽然 HALO 这个名字广为人知,但实际上 HALO 只是一个编译器优化特性,而不是一个语言特性。这意味着一个程序员不可能只看 Language Spec 而写出 HALO 友好的代码,程序员保证 HALO 的唯一办法即是不断地测试不同的编译器版本。
在 LLVM 中,HALO 被称为 CoroElide。我觉得 CoroElide 这个名字更好懂,所以我一直用这个名字,哪怕 HALO 确实看上去比较酷。
编译器自动实现 CoroElide 的条件 & 应用 tips
本节尝试在不深入编译器实现细节的前提下,描述编译器自动实现 CoroElide 的条件,向用户描述目前编译器实现 CoroElide 的限制。
一言以蔽之,编译器自动实现 CoroElide 的条件是:编译器可以证明这个协程帧的生命周期收敛于调用点所处的 Scope 中。即该协程帧会在进入该 Scope 后被创建,在退出该 Scope 前被销毁。
先来看一个正面的例子
#include <coroutine>
#include <iostream>
#include <cstdlib>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_value(int v) { value = v; }
void unhandled_exception() {}
int value = 0;
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
void resume() {
if (handle)
handle.resume();
}
void destroy() {
if (handle)
handle.destroy();
}
int value() {
if (handle)
return handle.promise().value;
return 0;
}
};
Task foo() {
co_return 43;
}
Task bar() {
auto f = foo();
while (!f.done())
f.resume();
int value = f.value();
f.destroy();
co_return value;
}
int main() {
auto b = bar();
while (!b.done())
b.resume();
std::cout << b.value() << std::endl;
b.destroy();
return 0;
}
编译并运行这个 case,结果为:
43
可以看到,包括 f = foo() 和 b = bar() 两个协程实例的动态分配都顺利地被编译器优化掉了。在 bar() 中,编译器可以明确 f = foo() 的协程帧在 auto f = foo(); 时被创建,在 f.destroy() 处被销毁。即 f = foo() 的协程生命周期必然收敛于 bar() 的 scope 中。b = bar() 在 main 函数中的过程也是类似的。
然而这种语法在稍微复杂的 case 中都是明显不可能被接受的。我们对这个 case 稍微重构下,让 Task 成为一个 awaiter,同时使用 symmetric transfer:
#include <coroutine>
#include <iostream>
#include <cstdlib>
#include <future>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
struct FinalAwaiter {
bool await_ready() noexcept { return false; }
std::coroutine_handle<> await_suspend(std::coroutine_handle<> h) noexcept {
if (continuation)
return continuation;
return std::noop_coroutine();
}
void await_resume() noexcept {}
std::coroutine_handle<> continuation;
};
FinalAwaiter final_suspend() noexcept { return {continuation}; }
void return_value(int v) { value = v; }
void unhandled_exception() {}
int value = 0;
std::coroutine_handle<> continuation;
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
bool await_ready() { return false; }
template <class Promise>
auto await_suspend(const std::coroutine_handle<Promise> &h) {
handle.promise().continuation = h;
return handle;
}
int await_resume() {
int value = handle.promise().value;
handle.destroy();
handle = nullptr;
return value;
}
};
int syncAwait(Task &&t) {
std::promise<int> p;
std::future<int> f = p.get_future();
auto lambda = [](std::promise<int> p, Task &&t) -> Task {
p.set_value(co_await t);
co_return 0;
};
auto h = lambda(std::move(p), std::move(t));
while (!h.done()) h.handle.resume();
h.handle.destroy();
return f.get();
}
Task foo() {
co_return 43;
}
Task bar() {
co_return co_await foo();
}
int main() {
std::cout << syncAwait(bar()) << std::endl;
return 0;
}
然后我们使用 (Clang >= 18) 编译后运行的输出是:
Coroutine allocated 48 bytes
Coroutine allocated 48 bytes
43
有两个协程的内存分配没有被编译器优化!(syncAwait 中的 lambda 协程动态分配被优化了(看汇编确定))
而如果我们使用(Clang <=17)编译输出后运行的话,结果却变成了:
Coroutine allocated 96 bytes
43
内存分配只发生了一次!bar() 中的 foo() 协程实例的内存帧被优化为 bar() 中的一个局部变量,然后这个局部变量被放到了 bar() 的协程帧中。导致 bar() 协程帧变大,但程序中的内存分配次数下降了,这是符合预期的。main 无法优化 bar() 的动态分配是因为 bar() 协程实例的结束标志位于 syncAwait() 中的 lambda 函数中,对于编译器来说过于难了。虽然在上帝视角上看我们是可以优化的,但从编译器实现者的视角看,这是符合预期的。
那在 Clang17 和 Clang18 之间发生了什么呢?答案是自从 Clang18 后,为了模仿标准中 await_suspend 的执行在协程暂停之后的描述, await_suspend 不再会被 inline (后文有更多描述)。
所以对于 Clang >=18 而言,上述例子中的 bar() 代码在经过 inline 优化后等价于:
Task bar() {
Task f;
f.handle = Task::promise_type::operator new(96); // #1
/* Initialize f.handle, ignored */
// f.await_ready() 总是被优化为 false
f.await_suspend(current_coroutine_handle()); // await_suspend 没有被 inline
// f.await_resume
int value = f.handle.promise().value;
f.handle.destroy(); // #2
f.handle = nullptr;
// co_return
current_promise.value = value;
return;
}
这里 #1 创建了 foo() 协程帧,#2 会销毁 foo() 协程帧。对人而言似乎一眼就可以断定 foo() 的协程帧生命周期收敛于 bar()。但对于编译器而言,f.await_suspend 没有被 inline,编译必须要假设 f.await_suspend 中可能会有这样的代码:
auto Task::await_suspend(std::coroutine_handle) {
...
another_handle = this->handle; // Not caring where another_handle comes from
this->handle = another_handle2; // this->handle changed!
...
}
当 f.await_suspend 中有这样的代码时,#2 所销毁的不再是 #1 中创建的协程帧,此时 #1 中创建的协程帧就不再会在 bar() 中被销毁,编译器也就无法证明 foo() 的协程帧生命周期收敛于 bar()。
那我们该怎么办呢?方法有:
- 通过属性,让程序员自动标记可 elide 的协程。这个在后文阐述。
- 理解编译器别名信息分析,帮助编译器证明生命周期收敛信息。
我们这里先描述第二种方法:
#include <coroutine>
#include <iostream>
#include <cstdlib>
#include <future>
struct Task {
struct promise_type {
void* operator new(std::size_t size) {
std::cout << "Coroutine allocated " << size << " bytes\n";
return ::operator new(size);
}
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
struct FinalAwaiter {
bool await_ready() noexcept { return false; }
std::coroutine_handle<> await_suspend(std::coroutine_handle<> h) noexcept {
if (continuation)
return continuation;
return std::noop_coroutine();
}
void await_resume() noexcept {}
std::coroutine_handle<> continuation;
};
FinalAwaiter final_suspend() noexcept { return {continuation}; }
void return_value(int v) { value = v; }
void unhandled_exception() {}
int value = 0;
std::coroutine_handle<> continuation;
};
std::coroutine_handle<promise_type> handle;
~Task() {
if (handle) handle.destroy();
}
bool done() const {
return handle && handle.done();
}
auto operator co_await() {
return Awaiter{handle};
}
struct Awaiter {
std::coroutine_handle<promise_type> handle;
bool await_ready() { return false; }
template <class Promise>
auto await_suspend(const std::coroutine_handle<Promise> &h) {
handle.promise().continuation = h;
return handle;
}
int await_resume() {
int value = handle.promise().value;
// handle.destroy();
handle = nullptr;
return value;
}
};
};
int syncAwait(Task &&t) {
std::promise<int> p;
std::future<int> f = p.get_future();
auto lambda = [](std::promise<int> p, Task &&t) -> Task {
p.set_value(co_await t);
co_return 0;
};
auto h = lambda(std::move(p), std::move(t));
while (!h.done()) h.handle.resume();
h.handle.destroy();
return f.get();
}
Task foo() {
co_return 43;
}
Task bar() {
auto f = foo();
int v = co_await f;
f.handle.destroy();
co_return v;
}
int main() {
std::cout << syncAwait(bar()) << std::endl;
return 0;
}
在 Clang >=18 的版本中编译运行后可以看到:
Coroutine allocated 96 bytes
43
和前一版主要的区别在于 Task 的 awaiter 实现:
auto operator co_await() {
return Awaiter{handle};
}
struct Awaiter {
std::coroutine_handle<promise_type> handle;
bool await_ready() { return false; }
template <class Promise>
auto await_suspend(const std::coroutine_handle<Promise> &h) {
handle.promise().continuation = h;
return handle;
}
int await_resume() {
return handle.promise().value;
// handle.destroy();
// handle = nullptr;
return value;
}
};
此时,bar() 中的实现等价于:
Task bar() {
Task f;
f.handle = Task::promise_type::operator new(96); // #1
/* Initialize f.handle, ignored */
Task::Awaiter awaiter{f.handle}; // Copy 构造
// awaiter.await_ready() 总是被优化为 false
awaiter.await_suspend(current_coroutine_handle()); // await_suspend 没有被 inline
// awaiter.await_resume
int value = awaiter.handle.promise().value;
// f.~Task()
// 编译器可以分析出 f.handle 必然不为 null。
f.handle.destroy(); #2
// co_return
current_promise.value = value;
return;
}
此时因为 awaiter 只拥有 f.handle 的复制值,而 f 和 f.handle 的地址没有通过任何方式被泄露,编译器可以确定无论 awaiter.await_suspend 的实现如何,#2 处的 f.handle 必然与 #1 处的 f.handle 指向同一个协程实例,所以编译器可以符合预期地完成 bar() 中的 foo() 协程的动态分配的优化,将其优化为 bar() 中的一个局部变量!
编译器优化机会
这里编译器可以给用户一个函数属性或者成员变量属性,用于让程序员提示编译器,这里的 await_suspend 不会修改 this->handle 的值或 this->handle 的值不会改变(设置为 nullptr 除外)。从而更大程度的使能 Coro Elide。
[[clang::coro_await_elidable]]
为了方便库作者应用 coro elide 优化,clang 引入了 [[clang::coro_await_elidable]] 类属性,其语义为:只要以该类为返回类型的协程函数的返回值被 立即 co_await 时,程序员向编译器保证,这个协程函数对应的协程实例是可以被 elide 的。
例如:
class [[clang::coro_await_elidable]] Task { ... };
Task foo();
Task bar() {
co_await foo(); // foo()'s coroutine frame on this line is elidable
auto t = foo(); // foo()'s coroutine frame on this line is NOT elidable
co_await t;
}
bar() 中第一行的 co_await foo(); 立即 co_await 了 foo() 协程的返回值,所以编译器可以认为该协程实例是可 elide 的,而第二行的 t = foo() 则没有立即被 co_await,所以不满足前面的约定。
这里的 立即 被 co_await 的说法对用户而言可能比较奇怪。这主要是由于实现的困难导致的。在前端的 AST 上做数据流分析很困难,所以为了折衷,我们选择了 立即 被 co_await 这样容易实现而且对于用户而言也较为容易理解的说法来实现。
编译器优化机会
前端做数据流分析虽然比较困难,但也不是不可能,如果我们可以做到前端判断一个协程实例是否 总是 会被 co_await ,那么我们就可以扩展这个属性的语义。同时我们也可以让 clang-tidy 中的安全检查更灵活一些。目前 cppcoreguidelines-avoid-capturing-lambda-coroutines 中不允许协程 lambda 有任何捕获,只其实过于严格了,很多是很好如果能保证其总会被 co_await,那可能就没什么问题。
[[clang::coro_await_elidable_argument]]
[[clang::coro_await_elidable_argument]] 属性主要是为了 whenall 语义做的扩展,目的是让 co_await whenall(foo(), bar(), zoo()) 中的 foo(), bar(), zoo() 等协程也可以被 Coro Elide 优化。
使用方式为:
template <typename T>
class [[clang::coro_await_elidable]] Task { ... };
template <typename... T>
class [[clang::coro_await_elidable]] WhenAll { ... };
// `when_all` is a utility function that composes coroutines. It does not
// need to be a coroutine to propagate.
template <typename... T>
WhenAll<T...> when_all([[clang::coro_await_elidable_argument]] Task<T> tasks...);
Task<int> foo();
Task<int> bar();
Task<void> example1() {
// `when_all``, `foo``, and `bar` are all elide safe because `when_all` is
// under a safe elide context and, thanks to the [[clang::coro_await_elidable_argument]]
// attribute, such context is propagated to foo and bar.
co_await when_all(foo(), bar());
}
Task<void> example2() {
// `when_all` and `bar` are elide safe. `foo` is not elide safe.
auto f = foo();
co_await when_all(f, bar());
}
Task<void> example3() {
// None of the calls are elide safe.
auto t = when_all(foo(), bar());
co_await t;
}
Is coro eliding always an optimization?
Background Story
我们很早就在内部大范围增强了 CoroElide 的能力,并预期通过降低内存分配次数获得正向性能收益。然而每次我们每次性能测试时,反而每次都在多数 case 上观察到了性能回退而非性能提升。
分析
内存占用
在实践中,很多时候协程和异步高并发编程是绑定的。那么可以预期,对于一个异步链路的入口,我们总是需要动态分配的:
Task zoo() {
something
}
Task foo() {
...
co_await zoo();
...
}
Task bar() {
...
co_await foo();
...
}
void entry() {
bar().start(callback); // 这是一个非阻塞调用!我们必须动态分配
...
}
此时若 foo() 和 zoo() 的协程帧动态分配都被 elide,那此时在 entry 中分配的内存为:
┌─────────────────────────────────────────┐
│ bar() 协程帧 │
│ ┌───────────────────────────────────┐ │
│ │ foo() 协程帧 │ │
│ │ ┌─────────────────────────────┐ │ │
│ │ │ zoo() 协程帧 │ │ │
│ │ │ 参数/局部变量 + 协程状态 │ │ │
│ │ └─────────────────────────────┘ │ │
│ │ │ │
│ │ 参数/局部变量 + 协程状态 │ │
│ └───────────────────────────────────┘ │
│ │
│ 参数/局部变量 + 协程状态 │
└─────────────────────────────────────────┘
我们需要一次性分配 sizeof(bar’s self states) + sizeof(foo’s self states) + sizeof(zoo’s self states) 这么多的内存。
而如果 foo() 和 zoo() 的协程帧都按需的动态进行分配,那么在 foo() 和 zoo() 执行之前或执行结束之后,实际的内存占用量反而会下降:
Memory
▲ ┌────────────────────────────────────────────────────────────┐
│ │█████████████████████████████ bar + foo + zoo ██████████████│
│ │████████████████████████████████████████████████████████████│
│ │████████████████████████████████████████████████████████████│
│ │████████████████████████████████████████████████████████████│
└──┴────────────────────────────────────────────────────────────┴──▶ time
bar.start bar.end
Memory
▲ ┌────────────────────────────────────────────────────────────┐
│ │ ███████████████████ │
│ │ ███████████████████ │
│ │ ███████████████████████████████████████ │
│ │████████████████████████████████████████████████████████████│
└──┴────────────────────────────────────────────────────────────┴──▶ time
bar.start foo.start() zoo.start zoo.end foo.end bar.end
当协程链路增加之后,很可能导致内存峰值反而比之前更高,而且导致内存占用率持续偏高。
编译器优化机会
可能需要在 Profiling 信息中增加新的维度,让编译器可以判断协程实例的生命周期长度,对于生命周期足够长的协程实例,我们可以认为 elide 这个协程的动态分配是有帮助的,而对于生命周期很短的协程实例,我们则可以倾向不 elide,同时协程帧的体积也应该是考虑的因素之一。
冷热信息
之前 LLVM 中 Coro Elide 的另一个问题是,LLVM 在编译时只要发现协程满足条件,就会进行 CoroElide “优化”,但这实际上并不总是一个优化。
例如:
Task foo() { ... }
Task bar(bool cond) {
if (cond) {
...
co_await foo();
...
}
...
}
如果实践中 cond 总是或几乎总是为 false,那么编译器对 if 语句中的 co_await foo(); 进行 CoroElide 优化就是一个负优化。这只会导致 bar() 协程帧变大而不会有任何正面作用。
在 Clang22 中,我们在 CoroElide 时加入了基于冷热信息的判断。在没有 Profiling 信息的情况下会使用静态分析判断冷热,原理大概是如果在循环里编译器就觉得比较热,如果在不在循环里而在 if 里,我们就觉得比较冷,那么就不会进行 CoroElide。
编译器优化机会
不过冷热信息判断目前只在使用 [[clang::coro_await_elidable_argument]] 时开启,对于不依赖程序员标注的自动 CoroElide,目前还没有用上这个属性。
CoroElide 的普遍限制 & 标准化
除了上述提到的限制之外,CoroElide 的一个重要限制是编译器必须在编译时看到被 elide 的协程的函数体。从而编译器才可以计算该协程的协程帧大小,然后才可以将协程帧转化为局部变量。
对目前的编译器而言,这一般靠 inline 来做到。后续可能可以只靠跨函数分析来达成。然而无论如何,在目前的单进程单文件的编译模型下,编译器无法拿到位于其他不可达的编译单元的协程实现的具体信息,导致无法进行 elide。
虽然理论上可以通过跨TU分析或 LTO 类似的技术来达成类似的目标,但这些限制导致了我们很难在 C++ 标准委员会推行 CoroElide 相关的 feature。
和语言协同的协程内存分配优化方案
标明协程帧体积上限、前端不透明的、显式协程帧类型
这个 Idea 的作者是 Lewis Baker,他的 paper 太多,我偷懒就没有细翻了,这里凭记忆描述下我印象最深的一种方式。
大概思路是让编译器前端计算出一个协程帧的上限大小,然后我们可以根据这个上限大小提前分配内存。然后提供一种方式,让程序员可以在不修改函数签名的情况下使用提前分配的内存作为协程帧的内存空间。
例如:
Task foo(...) { ... }
Task bar(...) { ... }
...
auto frame = decl_coro_frame_type(bar(a, b, c));
auto t = call_coro_with_specified_frame(bar(a, b, c), frame);
auto size = get_coro_frame_size_uplimit(foo(a, b, c));
void *buffer = personlized_allocator(size);
auto f = call_coro_with_specified_frame(foo(a, b, c), buffer);
这里的两个例子分别说明了通过编译器前端原语获取协程帧体积上限,然后使用局部变量或者调用自定义的内存分配器分配协程帧内存的用法例子。
这个 idea 是可实现的,只是:
- 依然要求协程实现在当前 TU 内可见。
- 要求编译器禁用目前的 CoroElide 优化。否则协程帧体积上限无从谈及。见前一节关于内存占用的描述,CoroElide 可能导致协程帧膨胀。
- 对于 Clang 这种依靠中端优化的实现,这种前端获取体积帧上限的方式,很可能导致获取的体积远大于实际所需体积(见第一节中 Clang VS GCC 的部分)。这对用户而言,很可能是个负优化。
其中 2,3 点则是我之前所描述的,Clang/LLVM 的协程实现选择反过来限制了协程语言设计的空间。
协程 elided allocation hook && stacked allocation
Idea 来源 MicroCai,https://github.com/alibaba/async_simple/discussions/398
大概思路为在 promise type 中提供一套新的 allocation 和 deallocation 的接口,当编译器决定 elide 时,不是简单粗暴地将协程帧转化为局部变量,而是尝试使用promise type 中提供的allocation 和 deallocation 的接口进行分配。这里的巧妙之处在于,这套 promise type 的 allocation 和 deallocation 分配器可以使用高效的栈式内存分配器。当我需要 allocation 时,直接增加栈指针即可,当然如果栈空间不够需要再申请。
这个设计的缺点有:
- 假设 elided 协程实例会按序进行构造和析构。这个假设比现在 CoroElide 的实现要求更强。比如前面提到的 Whenall 场景,目前的实现直接套用现在这个设计会比较危险。
- 这个设计只针对 Task 类型的经典协程。C++20 协程在设计上允许用户有非常强的扩展性。但这个设计只针对其中一种特定的协程,当然,这种协程确实算主流。
而在了解了上述静态 CoroElide 的缺陷后,这个方法的优势也比较明显:
- 避免了冷热路径的问题。
- 使用局部高效的 stacked allocation ,避免全局相对低效的内存分配。
- 可以避免过早提前分配导致内存开销过大的问题。
我自己也在编译器中实现了一版草稿:https://github.com/ChuanqiXu9/llvm-project/tree/StackedAllocation
相关的库实现在:https://github.com/alibaba/async_simple/commit/a13f69eb408fb7e7ce25ca1f75f42e84931ab71c 。感兴趣的朋友可以直接试用这个分支,也可以根据其实现,在自己的协程库里进行测试。
我准备找时间在大型应用上测试下效果。感兴趣的朋友也可以自己试用一下,跑一些小型 benchmark。
总结
CoroElide 是协程优化中最有名的优化,而由于动态分配的复杂性,很难静态地决定最佳的内存分配方法。(做过内存分配调优的朋友可能更有体会)。长期来看,这个领域在编译器、库、以及编译器和库协同实现等方向上都有很大的空间。
- 自动 CoroElide 由于 await_suspend 的变化,导致在 Clang18 后很多原来可以被自动 elide 的代码不能被自动 elide。在 Clang18 之后需要一些额外的 hack 来编写自动 elide 友好的代码。这里对编译器开发而言也需要提供额外的 attribute,让用户告知编译器,
await_suspend不会修改this->handle。 - Clang 更新的版本提供了
[[clang::coro_await_elidable]]属性,提供了确定性的协程 elide 机会。但是由于前端架构的原因,只能为 immediately awaited 的协程对象实现 elide。后续编译器前端要么强化这方面的数据流分析,要么还是需要基于中端能力的自动 Elide 功能。 - 静态的 CoroElide 不一定总是一个优化。这里对编译器而言可能有许多基于 Profiling 优化的机会,或者让用户更灵活提供 high level 信息的优化 hint 的可能。
- 编译器和库协同优化有比较大的空间。
noexcept
Background Story
在协程刚宣布进入标准之后,我们就开始尝试应用协程。当时因为编译器支持和库支持都比较原始,而且异步编程的生命周期问题比较难查,我们为了风险考虑,并没有直接将原来的同步链路一下子改成异步链路。而是考虑通过宏,让一套代码可以灵活地切换为基于协程的同步链路和基于协程的异步链路。
对比基于协程的同步链路和原来的同步链路时,我们发现了比较大的性能回退。我们很快定位到了是因为协程分配的原因,然后根据编译器实现优化了协程库的实现,使其可以被自动elide(当时 clang 版本还很低),然而我们还是发现了显著的性能差异。最后定位到是协程插入到 try-catch 导致的。
noexcept 自动传播
对于
void bar();
[[clang::noinline]] // 为了生成代码更好读
void foo() {
try {
bar();
} catch(...) {}
}
void zoo() {
try {
foo();
} catch (...) {
}
}
我们应该希望编译器可以自动(在中端)将 foo() 标记为 noexcept,从而在 zoo() 中消除掉无用的 try catch。
然而 Clang 目前却无法做到这一点:
clang++ -O3 -S -emit-llvm -o - %s
define dso_local void @zoo()() local_unnamed_addr #2 personality ptr @__gxx_personality_v0 !dbg !24 {
invoke void @foo()()
to label %5 unwind label %1, !dbg !25
1:
%2 = landingpad { ptr, i32 }
catch ptr null, !dbg !27
%3 = extractvalue { ptr, i32 } %2, 0, !dbg !27
%4 = tail call ptr @__cxa_begin_catch(ptr %3) #3, !dbg !28
tail call void @__cxa_end_catch(), !dbg !29
br label %5, !dbg !29
5:
ret void, !dbg !31
}
经过讨论,这似乎是语言标准中的一个“漏洞”(not confirmed),结论是,这取决于当一个异常的析构函数抛出异常时,程序应该处于什么行为。
例如若 bar() 的实现为:
struct E {
~E() noexcept(false) {
throw 3;
}
};
void bar() {
throw E();
}
那么即使 foo() 的实现已经用 catch(...) 尝试捕获住所有异常,目前编译器还是无法确定 foo() 一定不会抛出异常。
据我所知,标准委员会对是否允许异常的析构函数抛出异常,或者当异常的析构函数抛出异常时是什么样的行为,似乎还没有结论,但在 Clang 社区的角度,我们希望不要随便改变现有行为。所以我们没有做进一步的优化。但因为异常的析构函数抛出异常确实是比较少见的 case,我们提供了 -fassume-nothrow-exception-dtor 以让用户向编译器传达目前程序中不存在析构函数会抛出异常的异常的这一信息,从而让编译器可以放心优化:
clang++ -O3 -S -emit-llvm -o - %s -fassume-nothrow-exception-dtor
define dso_local void @zoo()() local_unnamed_addr #2 !dbg !24 {
tail call void @foo()(), !dbg !25
ret void, !dbg !27
}
能看到非常明显的优化效果。
和协程的关系
上面的讨论很有趣,但这和协程有什么关系呢?
答案是语言设计保证每一个协程都会被 try-catch 包裹住:
{
promise-type promise promise-constructor-arguments ;
try {
co_await promise.initial_suspend() ;
function-body
} catch ( ... ) {
if (!initial-await-resume-called)
throw ;
promise.unhandled_exception() ;
}
final-suspend :
co_await promise.final_suspend() ;
}
其中 final_suspend() 由语言保证不会 throw。那么如果协程库作者可以保证 promise.unhandled_exception() 不会 throw 且 co_await promise.initial_suspend() 及之前(协程帧分配以及 promise 构造)不会 throw 的话,那么这个协程类型的所有协程都可以被认为是不会 throw 的。此时配合上 -fassume-nothrow-exception-dtor,我们便可以自动为每一个协程自动添加 noexcept。从而触发更多优化。
Coro RVO
协程没有传统意义上的 return 语句,但调用协程函数,依然由 promise_type.get_return_object() 返回一个对象给调用者。
在 Clang 中,我们为这个返回实现 RVO 优化,即直接在调用者的返回槽中直接构造协程,避免反复构造传递的开销。
但后面由于实现层面的限制,现在协程中的 RVO 只会在协程返回类型和 promise_type.get_return_object() 的类型一致时才会启用。
await_suspend 的运行发生在协程暂停之后
标准提到,
[expr.await]p5.1 If the result of await-ready is false, the coroutine is considered suspended.
这意味着,在 await_suspend() 函数执行时,其所在协程已经被挂起了,即已经停止运行了。
而目前编译器生成的代码中,await_suspend() 实际上依然是在所在协程中执行的,我们是在 await_suspend() 执行结束后,根据 await_suspend() 返回的结果,判断是否继续进行,还是挂起(返回)。这么做的主要目的是更好的性能,除了可以 inline await_suspend() 之外,当 await_suspend() 判断依然需要执行时,我们不必真正的出栈再入栈,而是直接简单执行就好。
但在实践中我们发现了多个相关的 bug。最重要的是在 await_suspend() destroy 协程的用法。按照标准,这种用法没有问题,因为 await_suspend() 执行时协程已经被认为是挂起了。但按 LLVM 之前的实现方式,await_suspend() 执行时实际上依旧被认为是协程仍在执行。
为了修复这个 bug,我们不再 inline await_suspend() 以模仿标准的 wording。这也是之前提到 Clang18 开始,不再能自动 elide 的原因。
但需要注意,我们依然只是在模仿标准的 wording,而没有真正的把 await_suspend() 移出协程之外。
initial_suspend 不为 always_suspend 会生成较多代码且 block CoroElide 优化
目前 LLVM 编译协程过程对于 initial_suspend 不为 always_suspend 的协程相对不友好,会生成很多额外的代码。
原因是因为目前 LLVM 编译协程时的设计为将一个协程分解为 Ramp、Resume 和 Destroy 三部分:
- Ramp。负责协程内存分配,Promise 构造以及协程帧初始化。对应原协程函数。
- Resume。根据协程目前的状态跳转到不同的 suspend point。对应 std::coroutine_handle<>::resume()。
- Destroy。销毁协程帧。对应 std::coroutine_handle<>::destroy()。
目前 Ramp 和 Resume 的划分依据是第一个可以在编译期确定必然 suspend 的地方,即为 always_suspend 的 initial_suspend。现在的 Ramp 函数在 initial_suspend 是 always_suspend 时非常小,非常利于 inlining。
例如对于前文提到的 Task 协程,以 bar() 函数为例:
Task bar() {
auto f = foo();
int v = co_await f;
f.handle.destroy();
co_return v;
}
其生成的 Ramp 代码为:
define dso_local void @bar()(ptr dead_on_unwind writable writeonly sret(%struct.Task) align 8 captures(none) initializes((0, 8)) %0) local_unnamed_addr #0 personality ptr @__gxx_personality_v0 {
%2 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, ptr noundef nonnull @.str, i64 noundef 20)
%3 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::ostream& std::ostream::_M_insert<unsigned long>(unsigned long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, i64 noundef 96)
%4 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) %3, ptr noundef nonnull @.str.1, i64 noundef 7)
%5 = tail call noalias noundef nonnull dereferenceable(96) ptr @operator new(unsigned long)(i64 noundef 96) #28
store ptr @bar() (.resume), ptr %5, align 8
%6 = getelementptr inbounds nuw i8, ptr %5, i64 8
store ptr @bar() (.destroy), ptr %6, align 8
%7 = getelementptr inbounds nuw i8, ptr %5, i64 16
store i32 0, ptr %7, align 8
%8 = getelementptr inbounds nuw i8, ptr %5, i64 24
store ptr null, ptr %8, align 8
store ptr %5, ptr %0, align 8
%9 = getelementptr inbounds nuw i8, ptr %5, i64 88
store i2 0, ptr %9, align 8
ret void
}
然而当我们将其 initial_suspend 修改为 suspend_never 后:
define dso_local void @bar()(ptr dead_on_unwind writable writeonly sret(%struct.Task) align 8 captures(none) initializes((0, 8)) %0) local_unnamed_addr #0 personality ptr @__gxx_personality_v0 {
%2 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, ptr noundef nonnull @.str, i64 noundef 20)
%3 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::ostream& std::ostream::_M_insert<unsigned long>(unsigned long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, i64 noundef 56)
%4 = tail call noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) %3, ptr noundef nonnull @.str.1, i64 noundef 7)
%5 = tail call noalias noundef nonnull dereferenceable(56) ptr @operator new(unsigned long)(i64 noundef 56) #27
store ptr @bar() (.resume), ptr %5, align 8
%6 = getelementptr inbounds nuw i8, ptr %5, i64 8
store ptr @bar() (.destroy), ptr %6, align 8
%7 = getelementptr inbounds nuw i8, ptr %5, i64 16
store i32 0, ptr %7, align 8
%8 = getelementptr inbounds nuw i8, ptr %5, i64 24
store ptr null, ptr %8, align 8
store ptr %5, ptr %0, align 8
%9 = invoke noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, ptr noundef nonnull @.str, i64 noundef 20)
to label %10 unwind label %25
10:
%11 = invoke noundef nonnull align 8 dereferenceable(8) ptr @std::ostream& std::ostream::_M_insert<unsigned long>(unsigned long)(ptr noundef nonnull align 8 dereferenceable(8) @std::cout, i64 noundef 48)
to label %12 unwind label %25
12:
%13 = invoke noundef nonnull align 8 dereferenceable(8) ptr @std::basic_ostream<char, std::char_traits<char>>& std::__ostream_insert<char, std::char_traits<char>>(std::basic_ostream<char, std::char_traits<char>>&, char const*, long)(ptr noundef nonnull align 8 dereferenceable(8) %11, ptr noundef nonnull @.str.1, i64 noundef 7)
to label %14 unwind label %25
14:
%15 = invoke noalias noundef nonnull dereferenceable(48) ptr @operator new(unsigned long)(i64 noundef 48) #27
to label %16 unwind label %25
16:
%17 = getelementptr inbounds nuw i8, ptr %5, i64 40
store ptr %15, ptr %17, align 8
%18 = getelementptr inbounds nuw i8, ptr %15, i64 8
store ptr @foo() (.destroy), ptr %18, align 8
%19 = getelementptr inbounds nuw i8, ptr %15, i64 32
%20 = getelementptr inbounds nuw i8, ptr %15, i64 16
%21 = getelementptr inbounds nuw i8, ptr %15, i64 24
store ptr null, ptr %21, align 8
store i32 43, ptr %20, align 8
store ptr null, ptr %19, align 8
store ptr null, ptr %15, align 8
%22 = getelementptr inbounds nuw i8, ptr %15, i64 40
store i1 false, ptr %22, align 8
%23 = load ptr, ptr @std::__n4861::coroutine_handle<std::__n4861::noop_coroutine_promise>::_S_fr, align 8
invoke fastcc void %23(ptr nonnull @std::__n4861::coroutine_handle<std::__n4861::noop_coroutine_promise>::_S_fr)
to label %24 unwind label %25
24:
unreachable
25:
%26 = landingpad { ptr, i32 }
catch ptr null
%27 = extractvalue { ptr, i32 } %26, 0
%28 = tail call ptr @__cxa_begin_catch(ptr %27) #23
invoke void @__cxa_end_catch()
to label %29 unwind label %36
29:
%30 = getelementptr inbounds nuw i8, ptr %5, i64 32
%31 = load ptr, ptr %8, align 8
store ptr %31, ptr %30, align 8
store ptr null, ptr %5, align 8
%32 = getelementptr inbounds nuw i8, ptr %5, i64 48
store i1 true, ptr %32, align 8
%33 = icmp eq ptr %31, null
%34 = select i1 %33, ptr @std::__n4861::coroutine_handle<std::__n4861::noop_coroutine_promise>::_S_fr, ptr %31
%35 = load ptr, ptr %34, align 8
tail call fastcc void %35(ptr nonnull %34)
ret void
36:
%37 = landingpad { ptr, i32 }
cleanup
tail call void @operator delete(void*, unsigned long)(ptr noundef nonnull %5, i64 noundef 56) #23
resume { ptr, i32 } %37
}
这实际上包含了所有 Resume 函数的内容!大部分情况下协程函数的主要内容为于 Resume 函数中,而在 Ramp 函数中将 Resume 复制一遍意味着协程相关代码体积膨胀!而且在大型项目中,代码体积膨胀往往也会导致性能下降。
除了体积之外,这样的另外一个坏处是,协程 Ramp 函数增到会阻碍其被 inline 的机会。也会近一步的阻碍被 CoroElide 的机会。
编译器优化机会
对于 initial_suspend 不为 suspend_always 的协程,我们应该考虑在 initial_suspend 处强行插入到 Resume 函数的调用。这样会多一次函数调用,但可以大幅降低代码体积,也可以使能 CoroElide。
[[clang::coro_only_destroy_when_complete]]
因为协程可能在任意 suspend point 后被 destroy,协程的 destroy 函数需要对不同的 suspend point 做准备。
例如
A foo() {
dtor d;
co_await something();
dtor d1;
co_await something();
dtor d2;
co_return 43;
}
编译器生成的 destroy 函数可能是(伪代码)
void foo.destroy(foo.Frame *frame) {
switch(frame->suspend_index()) {
case 1:
frame->d.~dtor();
break;
case 2:
frame->d.~dtor();
frame->d1.~dtor();
break;
case 3:
frame->d.~dtor();
frame->d1.~dtor();
frame->d2.~dtor();
break;
default: // coroutine completed or haven't started
break;
}
frame->promise.~promise_type();
delete frame;
}
但作为 A 的协程库的设计者,如果我知道协程 A 的设计并不允许 Cancel 语义,即任何一个协程必然只在其完成后才会被销毁,上面生成的代码就很低效了。此时我们可以给 A 增加类属性 [[clang::coro_only_destroy_when_complete]] 以传达这一信息。此时编译器可以生成:
void foo.destroy(foo.Frame *frame) {
frame->promise.~promise_type();
delete frame;
}
编译器优化机会
[[clang::coro_only_destroy_when_complete]]这个信息可能太强了。因为现在可能很多协程库都支持 Cancel 语义。我们可能需要增加调用点或 suspend point 级别的属性,用于让用户告知编译器,这个地方的 suspend 一定会返回,从而实现更细粒度的优化。
例如
CancellableTask foo() {
[[clang::must_resume]] co_await something();
...
}
我们不能给 CancellableTask 标记 [[clang::coro_only_destroy_when_complete]]。但我们可以告述编译器,[[clang::must_resume]] co_await something(); 这里你是可以放心优化的。
[[clang::coro_only_destroy_when_complete]]除了优化 destroy 函数之外,本身还携带了这个类型的协程的每一个 suspend point 都最终会被 resume 的信息。这个信息可能可以用于优化,但目前并没有被很好的利用。
CIR
CIR 尝试通过在 Clang AST 和 LLVM IR 中建立一个新的抽象层来解决:
- 前端缺乏数据流分析的问题。
- 中端缺乏语言信息的问题。
似乎第一眼看上去 CIR 非常适合协程生成,可以避免我们之前提到的 false layering 的问题。但实际上 CIR 对于协程应该还是只能做分析为主,真正的代码生成必须要 delay 到目前生成协程帧的地方才行。原因是目前 LLVM 中生成协程帧的位置比较靠后,这是为了让协程代码充分的享受到中端优化的红利。如果我们直接将协程代码生成的功能往前提,几乎必然会导致性能 Regression。
但 CIR 对协程的性能应该依然是有帮助的。通过 CIR 层面的分析,我们可以插入更多的优化 hint 为 LLVM 优化协程代码做指导。
总结
对于用户:
- 使用 Clang 可以获得明显的性能提升。
- 使用
{}细化变量生命周期对缩小协程帧会有帮助。 - 确定代码库中不存在析构函数会抛出异常的异常后,可以启用
-fassume-nothrow-exception-dtor优化。 - 协程返回类型尽量与
get_return_object一致。
对于协程库作者:
- 可以尝试编写 CoroElide 友好的代码。(避免
this和this->handle逃逸) - CoroElide 并不一定总是个优化。但这里依然有很大的优化空间和机会。
- stacked allocation 可以尝试下。
- 若协程不会取消,可以考虑使用
[[clang::coro_only_destroy_when_complete]]。 - initial_suspend 尽量为
std::suspend_always。
对于编译器开发者:
- 考虑缩减协程局部变量的生命周期信息。需要注意逃逸分析。
- 协程相关的 Profiling 优化可能很有机会。例如结合 Profiling 信息的 CoroElide 优化。
- 和语言前端协同的优化机会比较多,让用户提供更多信息以进一步优化。